A múltkori Zopfli-bejelentés után fellángolt bennem a vágy, hogy újra betömörítsem az egyik mail folderemet (mbox formában lementve), és megnézzem, hogy melyik tömörítő hogy szerepel.
Sajnos csak odáig jutottam, hogy megírtam, majd elindítottam a scriptet, aztán el is felejtettem az egészet. De ma egy blogbejegyzés kapcsán eszembe jutott a dolog, így legeneráltam a képeket, és megírom a cikket, hátha valamire jó lesz. 🙂
Az “áldozat” a fent említett mbox formátumú fájl, kereken 100 megás. Van benne szöveg, kép, doc és egyéb csatolmányok (és pár spam is, bár ez ebből a szempontból irreleváns).
A gép, amelyen a teszteket futtattam két darab Intel Xeon E5-2680 (2,7 GHz, 8 mag, HT, így összesen 32 CPU látszik az OS-nek) CPU-t és 32 GB memóriát tartalmazott. A tesztek minden IO-ja ramdisken (tmpfs) történt, a használt OS FreeBSD 9 64 biten.
A tesztelt tömörítők: gzip, bzip2, lzma (az OS-ben lévő verziók), zopfli (git: acc035299f8dfe1ddcbc93c99f8600269790f88c), lz4 (svn r90) és a zpaq (6.22).
Magyarázat a grafikonokhoz:
Az x skálán minden képen 10 érték szerepel, ebből a legelső a nullás, amely némely tömörítőnél nem értelmezett (pld. gzip, bzip2). Az lz4-nek két tömörítési állapota van (fast és high), ezek a grafikonok 0-ás és 1-es részén szerepelnek.
A zopfli esetében iterációkat lehet megadni 5-től 1000-ig (kilenc lépcső), így annak értékei illeszkednek a gzip-bzip2 1-9-ig terjedő beállításaihoz. A zopflival gzip formátumba tömörítettem.
A sorból némileg kilóg a zpaq, hiszen az csak metaadatokkal (fájlok) ellátott archívot tud készíteni, így kicsit alma-körte jellegű a direkt gzip vs zpaq összehasonlítás a tar.gz vs zpaq helyett, de azt gondolom még így is érdekes lehet.
A zpaq csomagban elérhető zpipe-ot (amely képes streamet tömöríteni) nem vettem be a tesztbe.
A szálak számát ott ahol lehetett egyre vettem, hogy ne kerüljenek előnybe azok a tömörítők, amelyek több szálon is képesek működni.
Mivel is lehetne kezdeni, mint a tömörítési arányokkal?
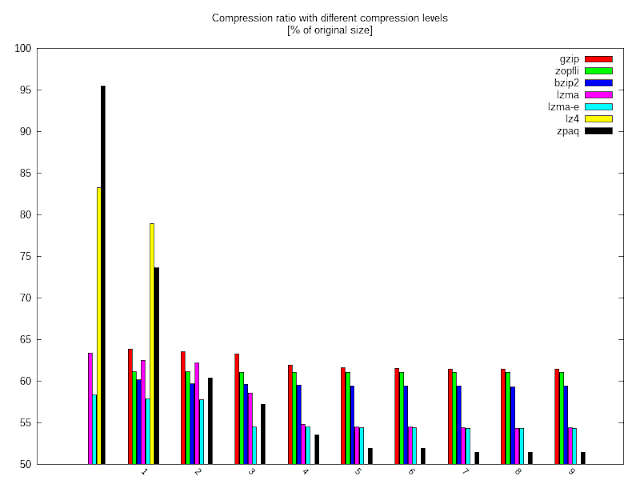
Mivel első körben a zopfli kapcsán készült a teszt, leginkább azt néztem. Rögtön szemet szúr, hogy az iterációk száma gyakorlatilag semmivel sem növelte a tömörítési hatékonyságot (a grafikonról egyáltalán nem látszik a különbség, számokban kifejezve is elenyésző: 0,11%. a skála két vége között). Lehet, hogy más típusú adaton jobban tud érvényesülni…
Dícséretes viszont, hogy az ígérethez híven végig verte a gzipet, a legnagyobb különbség 2,72%., a legkisebb 0,36 százalékpont.
Az árát majd később látjuk…
Az lz4 is hozza az ígértet, kevésbé tömörít, de gyorsan (ez is később). A bzip2 a szokásos köröket veri a gzipre, amit az lzma magasabb tömörítési fokozatokon (illetve az “extrém” kapcsolójával végig) tud csak überelni.
A saját kedvenc zpaq a 3-4-es fokozatnál kezd igazán aktív lenni, 9-esen pedig még mindig 2,9%.-ot ver az extrém tömörítős lzma-ra.
Node lássuk mennyi időt is kell várni a tömörítésre:
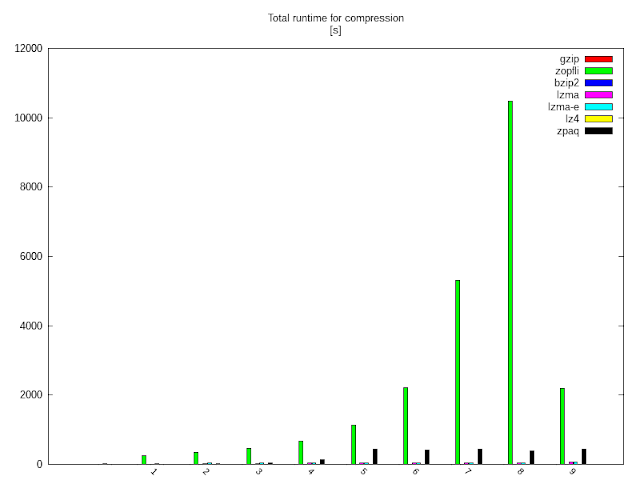
A grafikonon lényegében csak egy versenyző látszik, a google új adatközpont-gyilkosa a zopfli. Magasabb iterációknál egyértelműen viszi a pálmát lassúságban, de az előző grafikonnal összevetve megnyugodhatunk: úgyis feleslegesen pörög, 0,36%.-ért egyszerűen nem éri meg több, mint három órát (!) várni (YMMV utoljára: erre az adatra legalábbis).
Hogy látsszanak a többiek is, ugyanez zopfli nélkül:

és az lz4 kedvéért zpaq nélkül:

Az lz4 abszolút bajnok a tömörítési időben, a gyors opciójánál először azt hittem, hogy nem is tömörít, pedig de, sőt, ahhoz képest, hogy kb. annyi idő alatt lefut, mint a “cp src dst”, nem is rosszul. Talán nem véletlen, hogy a ZFS-be is ez lett az első nem Oracle tömörítő-kiegészítés.
A zpaq megkéri az árát a legjobb tömörítésnek, a leglassabb-dobogó harmadik helyére pedig -nem éppen váratlanul- az lzma(-e) állhat.
A CPU idő mellett már csak a memória szabhat gátat a tömörítési elképzeléseinknek, de hogy mennyire, az itt látható:

A zpaq sokat gondolkozik, cserébe jó nagy agy is kell neki. Hogy mekkora? Majdnem 5 GB…
Mint látható, kisebb fokozaton “jóval” kevesebbel is beéri. 🙂
zpaq nélkül a mezőny RSS foglalása:
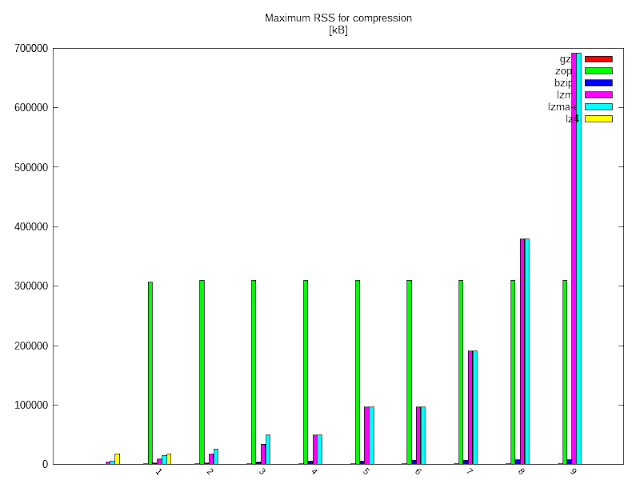
Mint látható, a zopfli cserébe azért, hogy alig tömörít jobban, nem is kér többet memóriából, ellenben az lzma-val, amely memóriahasználata szépen “skálázódik” a tömörítési fokkal.
Pozitív viszont, hogy az extrém tömörítés nem kerül extrém sok memóriába, a legalacsonyabb fokoktól eltekintve gyakorlatilag semennyivel sem többe.
Érdekes lehet még az lz4 viszonylag magas memóriaigénye, de szerencsére még koránt sem a kiugró érték (illetve lehet, hogy optimalizálható még), és sebességben bőven visszaadja.
A gzip és a bzip2 említést sem érdemel, gyakorlatilag beleolvad az x skálába.
CPU idők system és user különösebb kommentár nélkül:

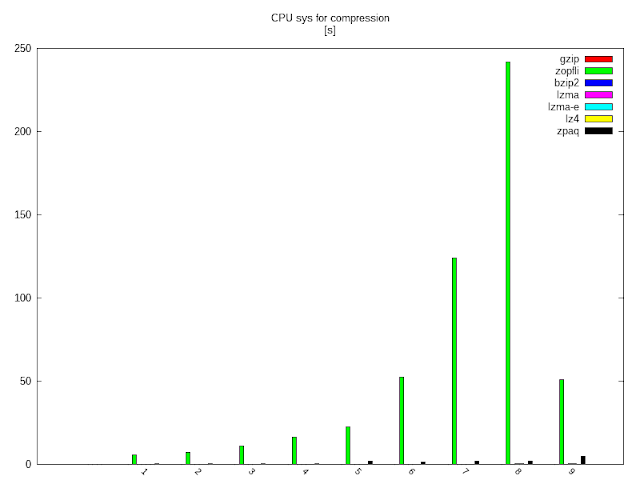
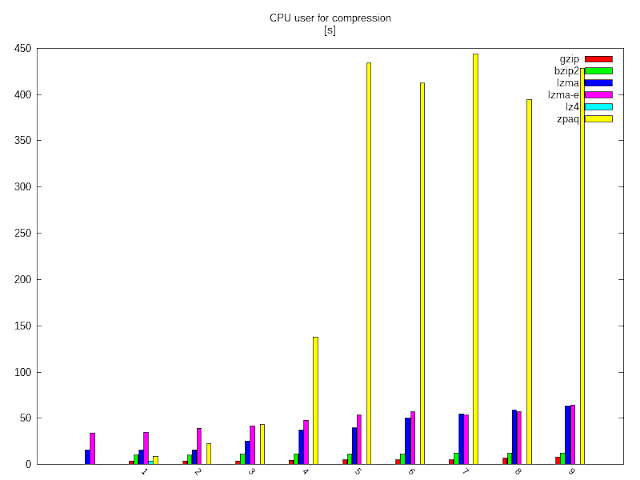
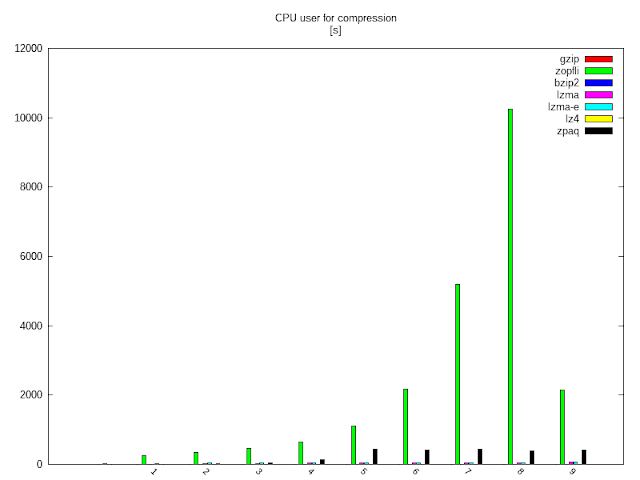
Majd a folyamat visszafelé: kitömörítés.
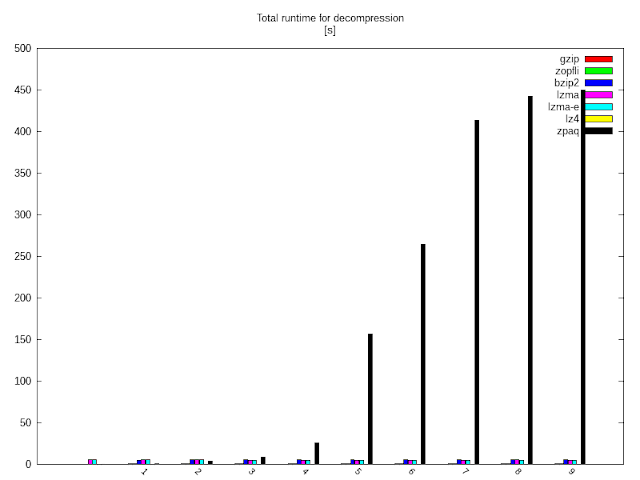
Látható, hogy a többiekkel ellentétben a zpaq meglehetősen szimmetrikus tömörítő, amit sokáig csomagol befelé, azzal bizony elszöszöl kifelé is.
Megtisztítva tőle a grafikont ezt kapjuk:

Sebességben továbbra is az lz4 a verhetetlen, az lzma stabilan veri a bzip2-őt, és annak ellenére, hogy a zopfli esetében a kitömörítés is gzippel történik, a jobban tömörített adat miatt szinte minden alkalommal rövidebb ideig tartott, mint az eredeti programmal.
A kitömörítéshez használt memória:

A zpaq a szimmetrikussága miatt itt is kikényszeríti, hogy nélküle is készüljön grafikon:
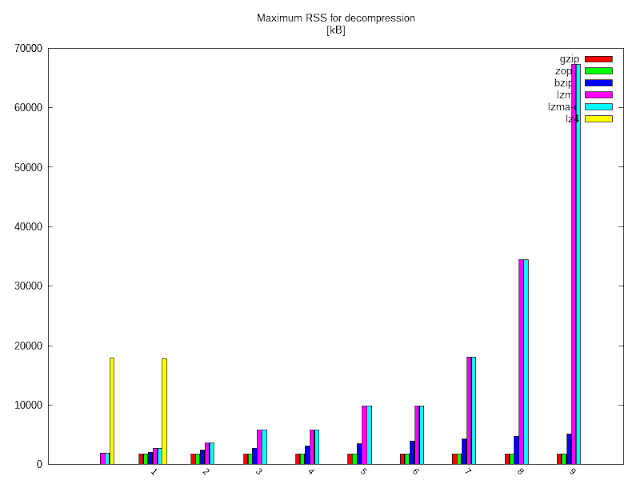
amelynél az elvárásoknak megfelelően a gzip-zopfli már tökéletesen együtt jár.
Végezetül álljanak itt a user-sys grafikonok:




és a végkövetkeztetés:
A zopfli ezen az adaton nem vizsgázott olyan jól a gzippel szemben, viszont stabilan hozta a nyereséget, amely a magasabb fokozatokra gyakorlatilag teljesen elolvadt, az ehhez szükséges tömörítési idő viszont már a zpaq idegtépő lassúságát is megszépíti, így gyakorlati alkalmazhatósága kérdéses a gzip -9-cel szemben.
A zpaq továbbra is favorit, bár így 2013 környékén a TB-ok már teljesen természetesek, a THz-ek viszont még nem, így legfeljebb azoknak ajánlható jó szívvel, akik még mindig 8 collos floppykra mentik az adataikat a 32 magos, 3 GHz-es gépeikről.
További jó tömörítést mindenkinek!